A GT OMSCS Course Review – High Performance Computer Architecture (CS6290)
For me, Georgia Tech’s OMSCS program’s biggest draw was it’s extensive machine learning and artificial intelligence curriculum. There are other online Master’s programs from well-regarded schools (University of Texas and University of Illinois immediately come to mind), but none as established as Georgia Tech and none with classes that felt worth the time and investment. However, through a quirk of scheduling (most of the ML/AI courses are in high demand and fill up quite quickly), three of my first four classes at GT have focused on computing systems.
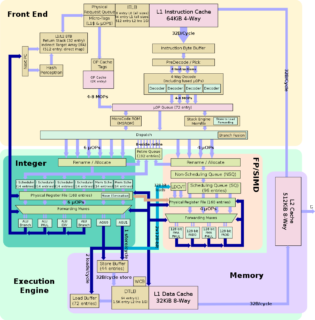
Now, it would be unfair to blame this purely on scheduling. It would have been quite easy to take different courses from different specializations, but I got into this program to learn and to challenge myself, and the computing systems offerings come highly recommended from the community of OMSCS students and are known for their difficulty. High Performance Computer Architecture (HPCA) certainly belongs in that conversation, and like the other computing systems courses that I’ve taken so far (Graduate Introduction to Operating Systems and Advanced Operating Systems being the other two), I left the class with a far better grasp on and appreciation for the internals of computers.

{kind=link}